
Transformers emerged as powerful methods for sequential recommendation. However, existing architectures often overlook the complex dependencies between user preferences and the temporal context.
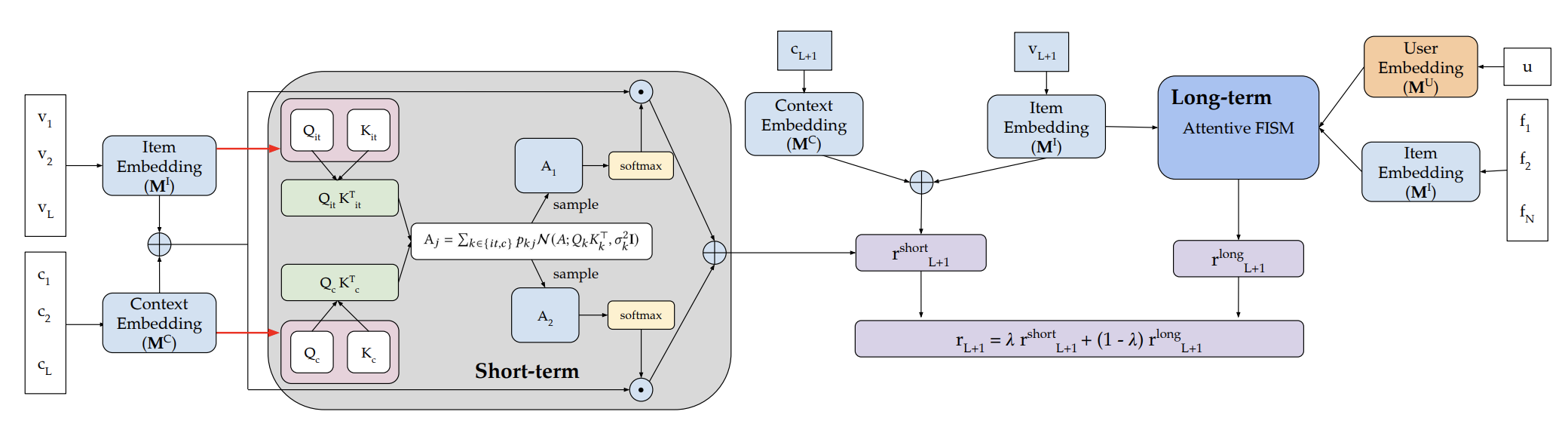
In this short paper, we introduce MOJITO, an improved Transformer sequential recommender system that addresses this limitation. MOJITO leverages Gaussian mixtures of attention-based temporal context and item embedding representations for sequential modeling. Such an approach permits to accurately predict which items should be recommended next to users depending on past actions and the temporal context.
We demonstrate the relevance of our approach, by empirically outperforming existing Transformers for sequential recommendation on several real-world datasets.
This paper has been accepted for publication in the proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2023).


