
Lyrics-to-audio alignment methods have recently reported impressive results, opening the door to practical applications such as karaoke and within song navigation. However, most studies focus on a single language - usually English - for which annotated data are abundant. The question of their ability to generalize to other languages, especially in low (or even zero) training resource scenarios has been so far left unexplored.
In this paper, we address the lyrics-to-audio alignment task in a generalized multi-lingual setup. More precisely, this investigation presents the first (to the best of our knowledge) attempt to create a language-independent lyrics-to-audio alignment system. Building on a Recurrent Neural Network (RNN) model trained with a Connectionist Temporal Classification (CTC) algorithm, we study the relevance of different intermediate representations, either character or phoneme, along with several strategies to design a training set.
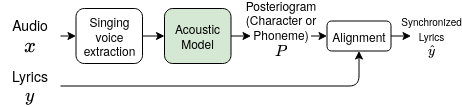
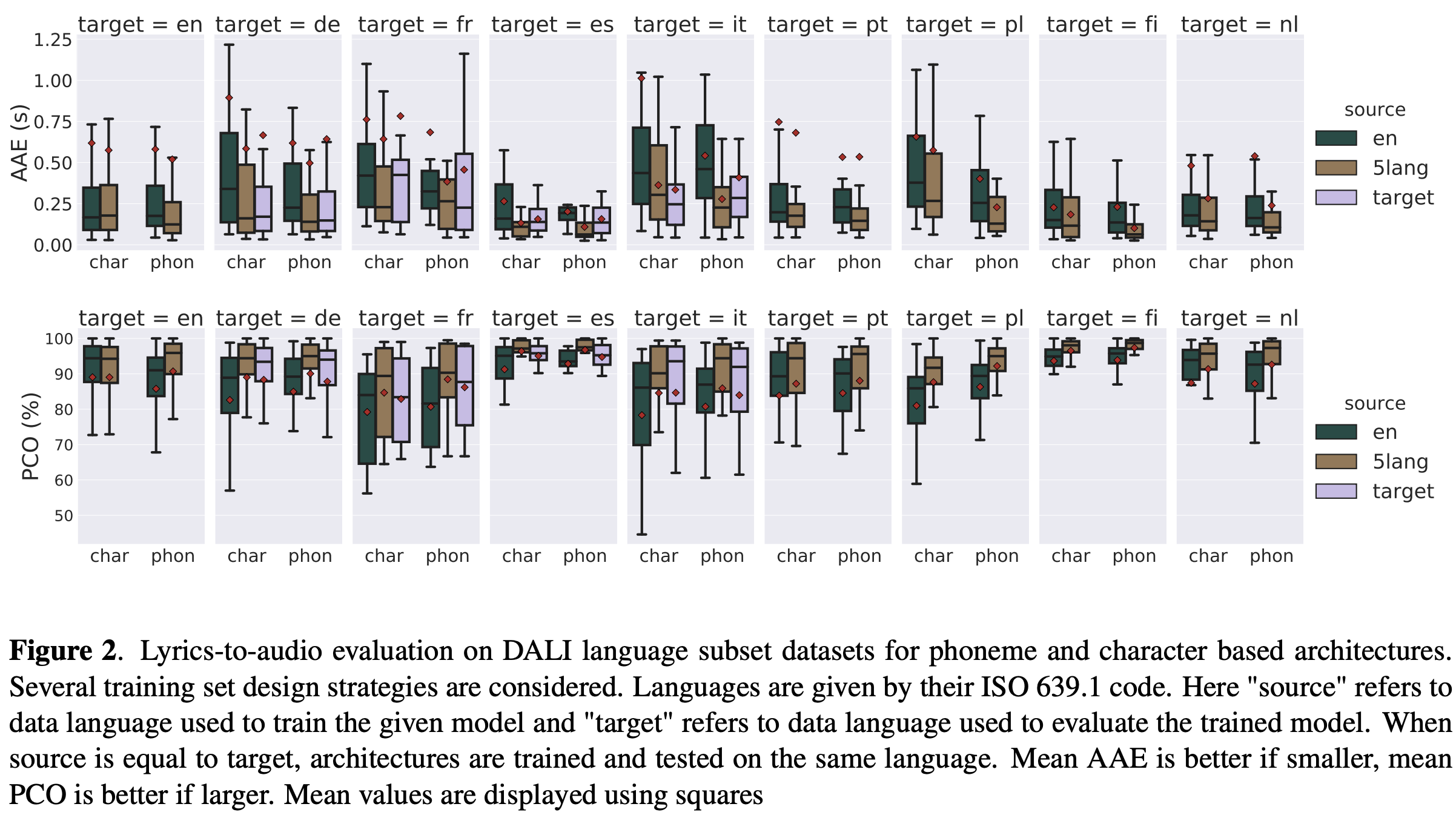
The evaluation is conducted on multiple languages with a varying amount of data available, from plenty to zero. Results show that learning from diverse data and using a universal phoneme set as an intermediate representation yield the best generalization performances.
This paper has been published in the proceedings of the 21st International Society for Music Information Retrieval Conference (ISMIR 2020).

