
In this paper, we consider the task of multimodal music mood prediction based on the audio signal and the lyrics of a track.
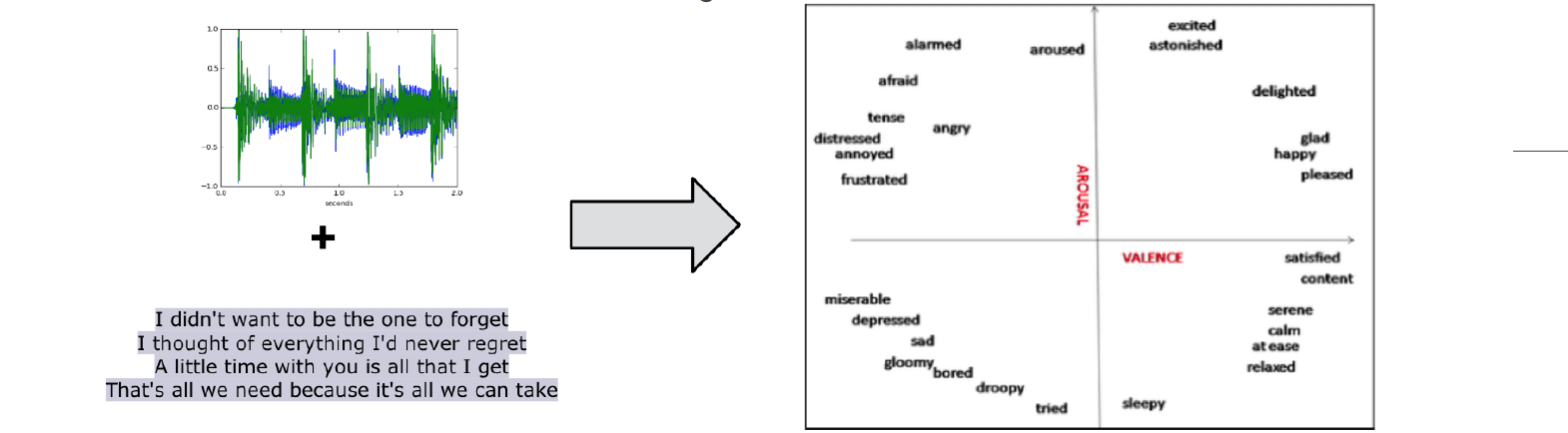
We reproduce the implementation of traditional feature engineering based approaches and propose a new model based on deep learning.
We compare the performance of both approaches on a database containing 18,000 tracks with associated valence and arousal values and show that our approach outperforms classical models on the arousal detection task, and that both approaches perform equally on the valence prediction task.
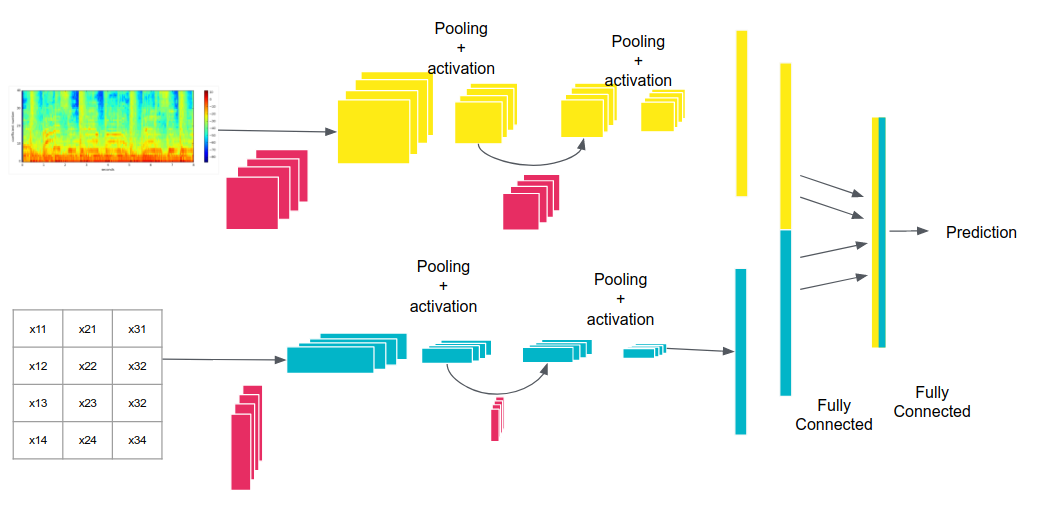
We also compare the a posteriori fusion with fusion of modalities optimized simultaneously with each unimodal model, and observe a significant improvement of valence prediction. We release part of our database for comparison purposes.

This paper has been published in the proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR 2018). It generated quite a large press coverage, for instance in Engadget.com (EN) or Clubic.com (FR).

